Environment Stats:
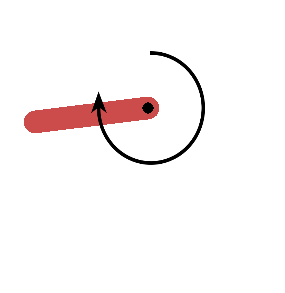
Description: Try to keep a frictionless pendulum standing up.
Action (Joint Effort) Min: -2.0 Max: 2.0
Reward: -(theta^2 + 0.1*theta_dt^2 + 0.001*action^2) Theta is normalized between -pi and pi. Therefore, the lowest cost is -(pi^2 + 0.1*8^2 + 0.001*2^2) = -16.2736044, and the highest cost is 0. In essence, the goal is to remain at zero angle (vertical), with the least rotational velocity, and the least effort.
Start State: Random angle from -pi to pi, and random velocity between -1 and 1
Stop State: None
Solve State: None
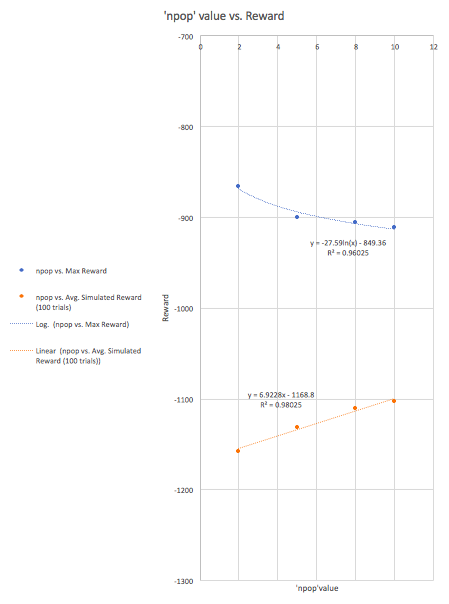
As a result, I felt I had to manually add to the code a ‘solve case’, which I placed at a reward of greater than -1000. Since the code began with a reward of ~-1700, I assumed that this would be a good benchmark for reinforcing the progress of the code.