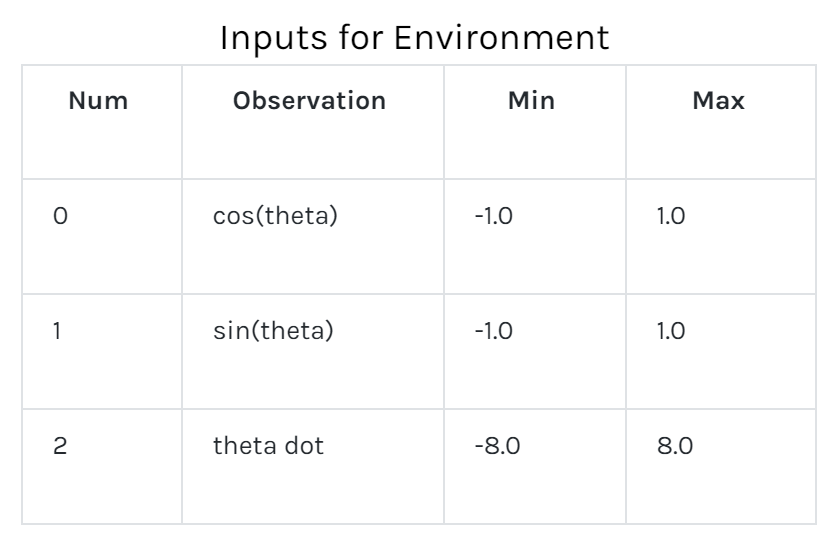
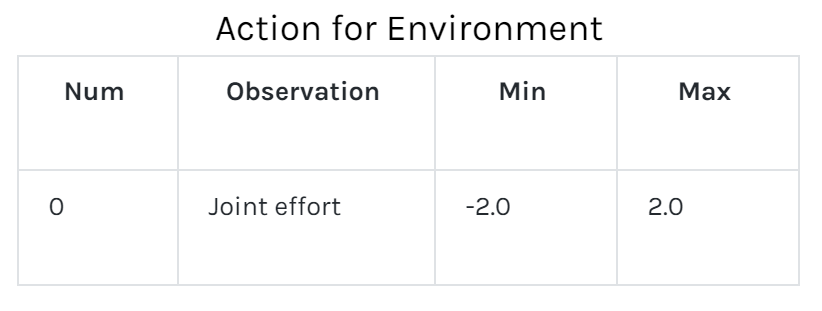
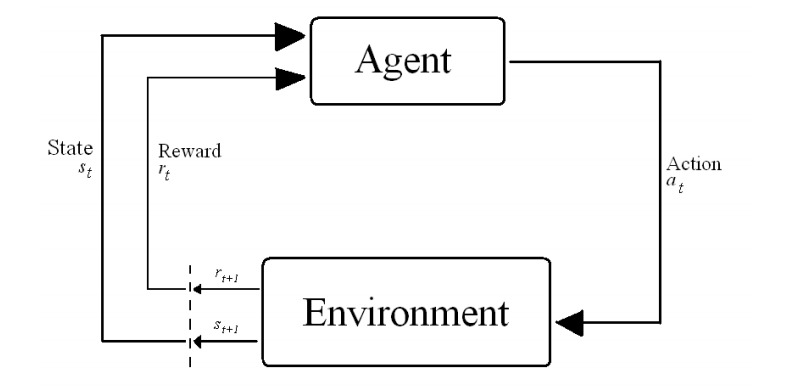
The agent learns by acting in the environment. Tasks in Reinforcement Learning are often modeled as Markov Decision Processes in which optimal actions over the state space S have to be found to optimize the total return over the process. At timestep t the agent is in state s and takes an action a ε A(s), where A(s) is the set of possible actions in s. It then transitions to state s
t+1 and receives a reward r
t+1 ε ℜ.
1
This process is outlined here:

Based on this interaction the agent must learn the optimal policy π*: S --> A to optimize the total return for a continuous task. 2
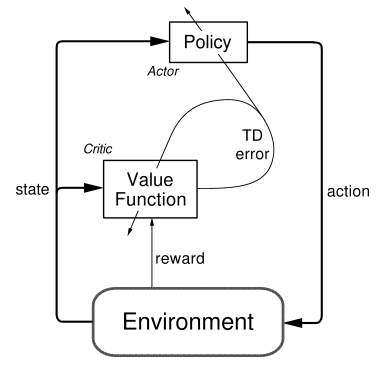
In Reinforcement Learning, learning the optimal policy is based on estimating state-value function, which expresses the value of being in a certain state. When the model of the environment is known, one can predict to what state each action will lead, and choose the action that leads to the state with the highest value.
The value for a certain state following policy π is given by this complicated Bellman Equation where π(s, a) is the chance of taking action a in s.
3
Therefore, the agent can learn the optimal policy π* by learning the optimal state-value function:  . 4
. 4
The task for the Cross Entropy method is to optimize the weights of this state-value function V(s), which determines the action of the agent, for each state using a linear value function with weights w and features Φ defining the value of a state for n features.
The core idea of the CE method is to sample the problem space and approximate the distribution of good solutions by assuming a distribution of the problem space, sampling the problem domain by generating candidate solutions using the distribution, and updating the distribution based on the better candidate solutions discovered. Samples are constructed step-wise (one component at a time) based on the summarized distribution of good solutions. As the algorithm progresses, the distribution becomes more refined until it focuses on the area or scope of optimal solutions in the domain.
5
The random sample is generated here:

Weights are updated here to produce a better sample in the next iteration:

1. ["Cross Entropy Method for Reinforcement Learning" by Steijn Kistemaker http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.224.3184&rep=rep1&type=pdf]↩
2. [ibid]↩
3. [ibid]↩
4. [ibid]↩
5. [ibid]↩